|
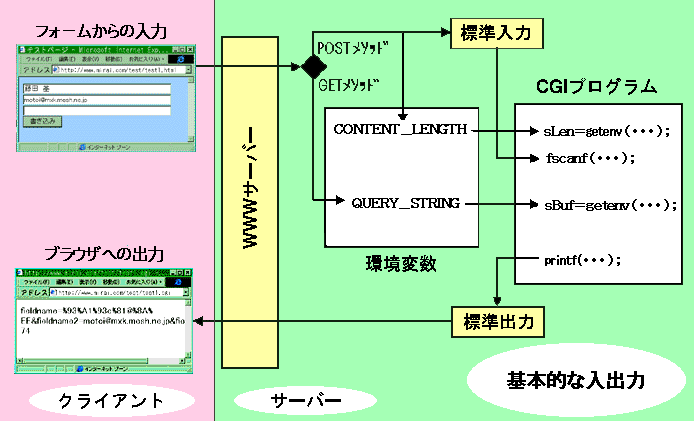
図のような簡単なフォームを作って、データをCGIプログラムで
読み込み、受け取ったままのデータをブラウザに表示してみましょう。 このままでは、まだデコードしていないので、訳が分かりませんが、 入力データがどのように送られてくるのかを見てください。 |
<HTML>
<HEAD>
<TITLE>テストページ</TITLE>
</HEAD>
<BODY BGCOLOR=#a0d0ff>
<FORM METHOD="get" ACTION="test2.cgi">
<INPUT TYPE="text" NAME="fieldname" SIZE="50"><BR>
<INPUT TYPE="text" NAME="fieldname2" SIZE="50"><BR>
<INPUT TYPE="text" NAME="fieldname3" SIZE="50"><BR>
<INPUT TYPE="submit" VALUE="書き込み">
</FORM>
</BODY>
</HTML>
| 左が、上に示したフォームのためのHTMLドキュメントです。 フォームから3つのデータを受け取って、test2.cgiという CGIプログラムを起動します。GETメソッドを指定しているので、 データの文字列は環境変数QUERY_STRINGにセットされます。 |
#include <stdio.h>
#include <stdlib.h>
#define getenv1(a) ((pdata=getenv(a)) ? pdata : "(NULL)")
main()
{
int len;
printf("Content-type: text/html\n\n");
printf("<HTML><HEAD></HEAD><BODY>\n");
printf("%s<BR>\n",getenv("QUERY_STRING"));
printf("</BODY></HTML>\n");
}
|
このプログラムについては、ほとんど説明不要と思います。
環境変数QUERY_STRINGを受け取ってプリントしているだけです。 getenv()の戻値がNULLであったときの対応をしていますが、 これは古いCコンパイラで、printf()にnullポインタが渡されると、 不正な動作をするためです。 |
でコンパイルした後、次のように、nobodyにも実行出来るようにします。cc -o test2.cgi test2.c
chmod 755 test2.cgi
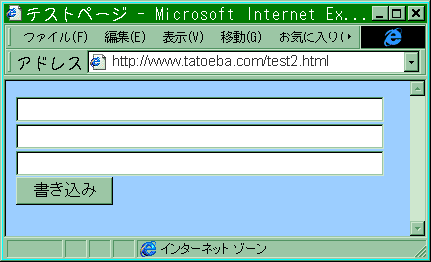
うまくいったら、WWWで実行してみましょう。 上で作ったフォームのそれぞれのフィールドに以下のように入力して、 送信ボタンを押して下さい
123次のように表示されたでしょう。
abc
ABC
フォームからの入力は、fieldname=123&fieldname2=abc&fieldname3=ABC
というようにエンコードされて、サーバーに渡されるのです、 このページの(3)でこのデータをデコードする例を示します。フィールド名1=値1&フィールド名2=値2・・・
<HTML>
<HEAD>
<TITLE>テストページ</TITLE>
</HEAD>
<BODY BGCOLOR=#a0d0ff>
<FORM METHOD="post" ACTION="test1.cgi">
<INPUT TYPE="text" NAME="fieldname" SIZE="50"><BR>
<INPUT TYPE="text" NAME="fieldname2" SIZE="50"><BR>
<INPUT TYPE="text" NAME="fieldname3" SIZE="50"><BR>
<INPUT TYPE="submit" VALUE="書き込み">
</FORM>
</BODY>
</HTML>
| 左が、上に示したフォームのためのHTMLドキュメントです。 GETメソッドにしめしたドキュメントと同様のフォームを生成します。 フォームから3つのデータを受け取って、test1.cgiという CGIプログラムを起動します。POSTメソッドを指定しているので、 データの文字列は標準入力ストリームに流され、文字列の長さが、 環境変数CONTENT_LENGTHにセットされます。 |
#include <stdio.h>
#include <stdlib.h>
main()
{
int len;
char *clen;
char *data;
clen=getenv("CONTENT_LENGTH");
if(clen==NULL){
printf("no contents.\n");
exit(1);
}
len=atol(clen);
data=malloc(len+1);
scanf("%s",data);
data[len]='\0';
printf("Content-type: text/html\n\n");
printf("<HTML><HEAD></HEAD><BODY>\n");
printf("%s<BR>\n",data);
printf("</BODY></HTML>\n");
}
|
POSTメソッドなので、環境変数CONTENT_LENGTHがら、
文字列の長さを受け取って、バッファを作成します。
次にscanf()でデータを標準入力から取得します。
でコンパイルした後、次のように、nobodyにも実行出来るようにします。
|
シェルでうまくいったら、WWWでやってみましょう。
<HTML>
<HEAD>
<TITLE>テストページ</TITLE>
</HEAD>
<BODY BGCOLOR=#a0d0ff>
<FORM METHOD="post" ACTION="test.cgi">
<INPUT TYPE="text" NAME="fieldname" SIZE="50"><BR>
<INPUT TYPE="text" NAME="fieldname2" SIZE="50"><BR>
<INPUT TYPE="text" NAME="fieldname3" SIZE="50"><BR>
<INPUT TYPE="submit" VALUE="書き込み">
</FORM>
</BODY>
</HTML>
| 左に示したHTMLはフォームデータを 以下に示すCGIプログラムに送信する ものです。特に説明は要らないですね。 |
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
main()
{
char *inputstring,*agent,*cLength,*name[20],*value[20];
int nfield;
long i,length,MAXLEN=4096;
int decode_form(),parse_form();
cLength=(char*)getenv("CONTENT_LENGTH");
length=atol(cLength);
if(length>MAXLEN) {printf("CONTENT_LENGTH>MAXLEN\n");exit(0);}
inputstring=(char*)malloc(length+1);
scanf("%s",inputstring);
printf("%s","Content-type: text/html\n\n\0");
printf("%s","<HTML><HEAD></HEAD><BODY>\n\0");
parse_form(inputstring,MAXLEN,name,value,&nfield);
for(i=0;i<nfield;i++){
decode_form(name[i],strlen(name[i]));
decode_form(value[i],strlen(value[i]));
printf("%s ---> %s<BR>\n",name[i],value[i]);
}
printf("%s","\n</BODY></HTML>\n\0");
free(inputstring);
exit(0);
}
| フォームからPOSTメソッドで入力を受け取り、 デコードして表示するプログラム例です。 環境変数CONTENT_LENGTHを取得して、バッファを準備し、 そこにフォームの内容を読み込みます。 後は、下に示すルーチンでフォームの切り分け(parse_form())と、 デコード(decode_form())を行います。 |
int parse_form(char* s_in,long maxl,char* name[],char* value[],int *p_nfld)
{
int i,cur_field;
*p_nfld=0;
i=0;
cur_field=0;
if(s_in[0]==NULL) return(-1);
name[0]=s_in;
while((s_in[++i]!=NULL)&&(i<maxl)){
if(s_in[i]=='='){
s_in[i]=NULL;
value[cur_field]=s_in+i+1;
}
else if(s_in[i]=='&'){
s_in[i]=NULL;
cur_field++;
name[cur_field]=s_in+i+1;
}
}
*p_nfld=cur_field+1;
return(0);
}
| フォームを切り分けるルーチンの例です。 s_inは入力文字列へのポインタです。 このルーチンでは、入力文字列のバッファを出力文字列の バッファとしても再利用しています。 気持ちの悪い人は、書き直して下さい。 maxlは最大の入力の長さ、name[]、value[]は、それぞれ フィールド名、値のポインタの配列、p_nfldは解析された フィールド数へのポインタです。 |
int decode_form(char* s,long len)
{
int i,j;
char buf,*s1;
if(len==0)return(-1);
s1=(char*)malloc(len);
for(i=0,j=0;i<len;i++,j++)
{
if(s[i]=='+'){s1[j]=' ';continue;}
if(s[i]!='%') {s1[j]=s[i];continue;}
buf=((s[++i]>='A') ? s[i]-'A'+10 : s[i]-'0');
buf*=16;
buf+=((s[++i]>='A') ? s[i]-'A'+10 : s[i]-'0');
s1[j]=buf;
}
for(i=0;i<j;i++) s[i]=s1[i];
s[i]='\0';
free(s1);
return(0);
}
| 16進のコードをデコードするルーチンです。 %16進数というところに当たると、 ここの部分を通常のバイナリに置き換えます。 このルーチンもあまり説明は要らないと思います。 |
nkfsub(char* cp,char* s_in,char* s_out)です。
”s” シフトJIS”j”を指定する時には(まああまりないと思いますが) ターゲットの文字列はシフトJISやEUCの倍くらいになりますので、 ターゲット用のバッファは十分大きく取って下さい。
”j” JIS
”e” EUC